通过本套课程的学习,可以积累大量Spark项目经验,迈入Spark高级开发行列。 课程特色: 1、项目中全面覆盖了Spark Core、Spark SQL和Spark Streaming这三个技术框架几乎全部的初级和高级的技术点和知识点, 让学员...
”spark 大量实战“ 的搜索结果
MapReduce总是消耗大量时间排序,而有些场景不需要排序,Spark可以避免不必要的排序所带来的开销 Spark是一张有向无环图(从一个点出发最终无法回到该点的一个拓扑),并对其进行优化。 4. Spark支持的API ...
1 Spark简介1.1 引言行业正在广泛使用Hadoop来分析他们的数据集。原因是Hadoop框架基于简单的编程模型(MapReduce),它使计算解决方案具有可扩展性,灵活性,容错性和成本效益。在这里,主要关注的是在查询之间的等待...
Spark 抽象、架构与运行环境 本课时我们进入:“Spark 抽象、架构与运行环境”的学习。从这个模块开始,我们会开始学习 Spark 的具体技术,本模块的内容主要包含两部分: Spark 背后的工程实现; Spark 的基础编程...
1、Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor; l驱动程序(Driver Program):运行Application的main()函数并且创建...
Spark内存计算框架在大数据处理领域内占有举足轻重的地位,2014年Spark风靡IT界,Twitter数据显示Spark已经超越Hadoop、Yarn等技术,成为大数据处理领域中最热门的技术,如图1所示。2015年6月17日,IBM宣布它的...
Spark基础入门篇 | MapReduce原理 + Spark原理 + PySpark环境搭建 + 简单实战

Phoenix 是一个开源的 HBASE SQL 层。它不仅可以使用标准的 JDBC API 替代 HBASE client API 创建表,插入和查询 HBASE,也支持二级索引、事物以及多种 SQL 层优化。
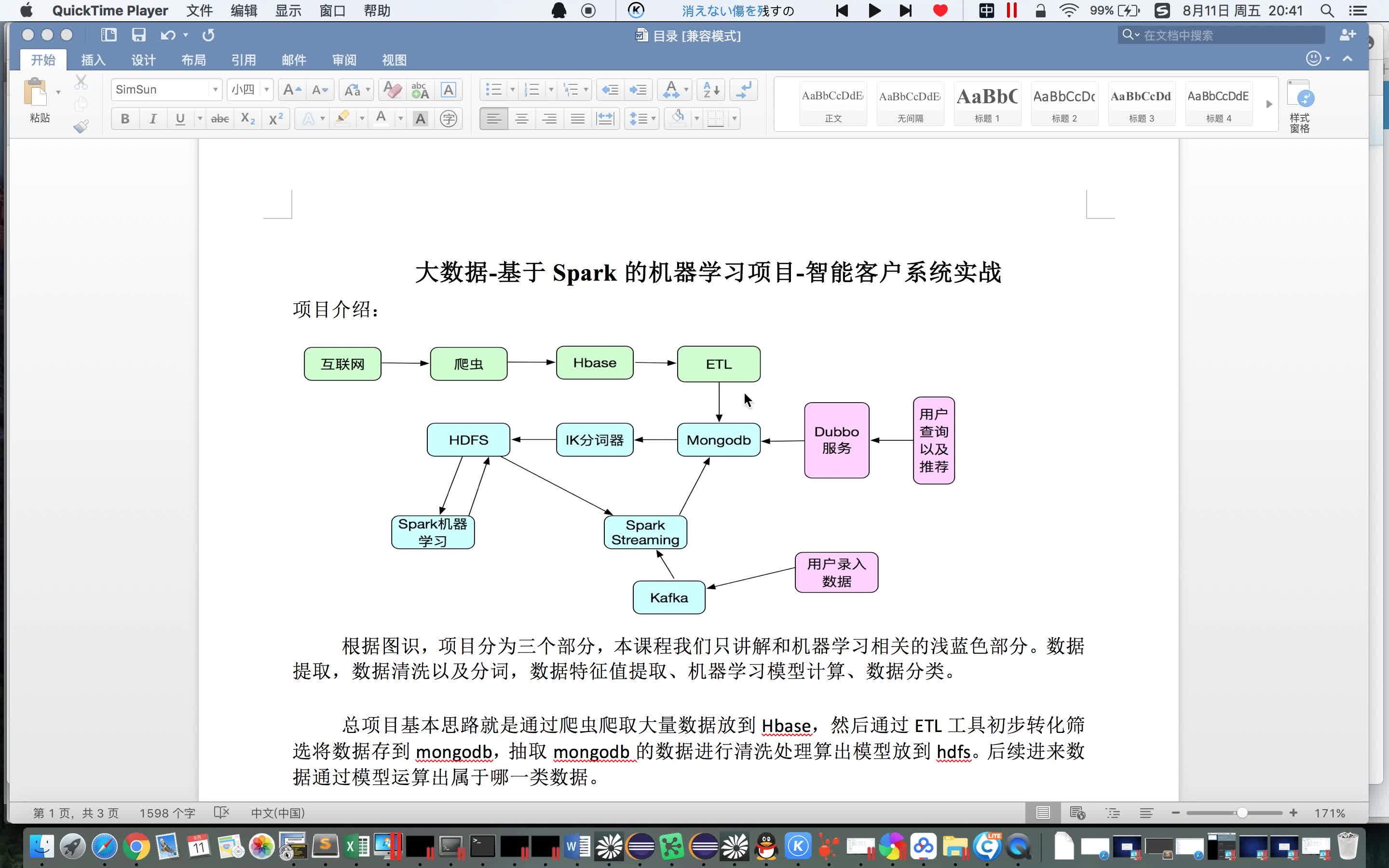
整个项目基本思路是如何通过爬虫爬取大量数据放到Hbase,然后通过ETL工具初步转化筛选将数据存到mongodb,抽取mongodb的数据进行清洗处理算出模型放到hdfs。后续进来数据通过模型运算出数据的类型。项目系统主要包括...
Apache Spark+PyTorch 案例实战 随着数据量和复杂性的不断增长,深度学习是提供大数据预测分析解决方案的理想方法,需要增加计算处理能力和更先进的图形处理器。通过深度学习,能够利用非结构化数据(例如图像、文本...
在本模块中,我们将学习 Spark 如何处理图,也就是 Spark 的图挖掘套件 GraphX。虽然图这种数据结构在最近几年中,越来越多地出现在业务场景中,但平心而论,图的使用频率相比前面所学的内容还没有那么频繁。但是,...
很多企业为了支持决策分析而构建的数据仓库系统,其中存放的大量历史数据就是静态数据。技术人员可以利用数据挖掘和OLAP(On-Line Analytical Processing)分析工具从静态数据中找到对企业有价值的信息 对...

join操作在进行数据处理时非常常见,而spark支持多种join类型。本文对spark中多种Join类型进行说明,并对不同join的使用场景进行了介绍和举例说明。 使用join操作的注意事项 在两个数据集比较的列有唯一值,使用...
Tungten 和 Hydrogen:Spark 性能提升与优化计划 在前面的课时中,我们学习了 Spark 的用法和原理,今天这个课时主要介绍 Spark 两个比较重要的优化提升项目,从这两个项目中可以看出 Spark 的优化思路。 这节课与...
Standalone模式提交Spark应用的机器,Application(自己的Spark程序),spark-submit(shell)提交Application。Driver(启动一个进程),spark-submit使用Standalone模式提交Application的时候,其实会通过反射的...
Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介 【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》1、SparkSQL的发展历程 石山园 Spark入门实战系列--6....
而spark,也是市面上批处理最好的计算引擎,它是你的必备技能立足于内存计算,性能超过Hadoop百倍,采用一个统一的技术堆栈解决了云计算大数据的如流处理、图技术、机器学习、NoSQL查询等方面的所有核心问题,具有...
文章目录一.GraphX 介绍二.GraphX 实现分析2.1 图的切分方式2.2 数据处理2.3 BSP模型2.4 设计核心三.GraphX 实例3.1 创建3.2 转换操作3.2.1 基本信息3.2.2mapVertices3.2.3 mapEdges3.2.4 mapTriplets3.3 结构操作...
1、机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。...
6、大量全网唯一的知识点:基于排序的wordcount,Spark二次排序,Spark分组取topn,DataFrame与RDD的两种转换方式,Spark SQL的内置函数、开窗函数、UDF、UDAF,Spark Streaming的Kafka Direct API、...
这一步在真实环境中会花费大量时间,尤其是数据量特别大的情况,因为通常会涉及巨量的读写性能消耗。 在不同的业务场景下,业务数据库通常会有不同的选择,主要分为两类:关系型数据库和NoSQL 数据库。 关系数据库...
Spark大数据计算框架、架构、计算模型和数据管理策略及 Spark在工业界的应用。围绕 Spark的 BDAS项目及其子项目进行了简要介绍。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、...
推荐文章
- 【解决报错】java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)-程序员宅基地
- echart y轴显示小数或整数_echarts y轴显示16位小数-程序员宅基地
- Android客户端和Internet的交互_android与internet-程序员宅基地
- linux新建分区步骤_linux创建基本分区的步骤-程序员宅基地
- 信号处理-小波变换4-DWT离散小波变换概念及离散小波变换实现滤波_dwt离散小波变换进行滤波-程序员宅基地
- Ubuntu 10.10中成功安装ns-allinone-2.34_进入/home/ubuntu1/ns-allinone-2.34目录cd /home/ubuntu1-程序员宅基地
- 使用AES算法对字符串进行加解密_java 判断aes加密 与否-程序员宅基地
- DFS深度优先搜索(前序、中序、后序遍历)非递归标准模板_深度优先搜索 无递归-程序员宅基地
- 程序员面试字节跳动,被怼了~_字节跳动java什么技术站-程序员宅基地
- 嵌入式软考备考(五)安全性基础知识-程序员宅基地